Nur gute Roboterhardware zu haben, wird keine Tore erzielen, stattdessen muss jemand den Robotern sagen, was sie tun sollen. Und da kommt unsere künstliche Intelligenz ins Spiel. Es läuft auf einem Computer neben dem Spielfeld und verwendet die Sichtdaten, die Schiedsrichterbefehle und das Feedback des Roboters, um Befehle zu generieren, die dann an unsere Roboter ausgegeben werden. Um eine geringe Reaktionszeit zu erreichen, müssen die Strategieentscheidungen sehr häufig (in unserem Fall bis zu 100 Mal pro Sekunde) neu bewertet werden.
KI-Architektur
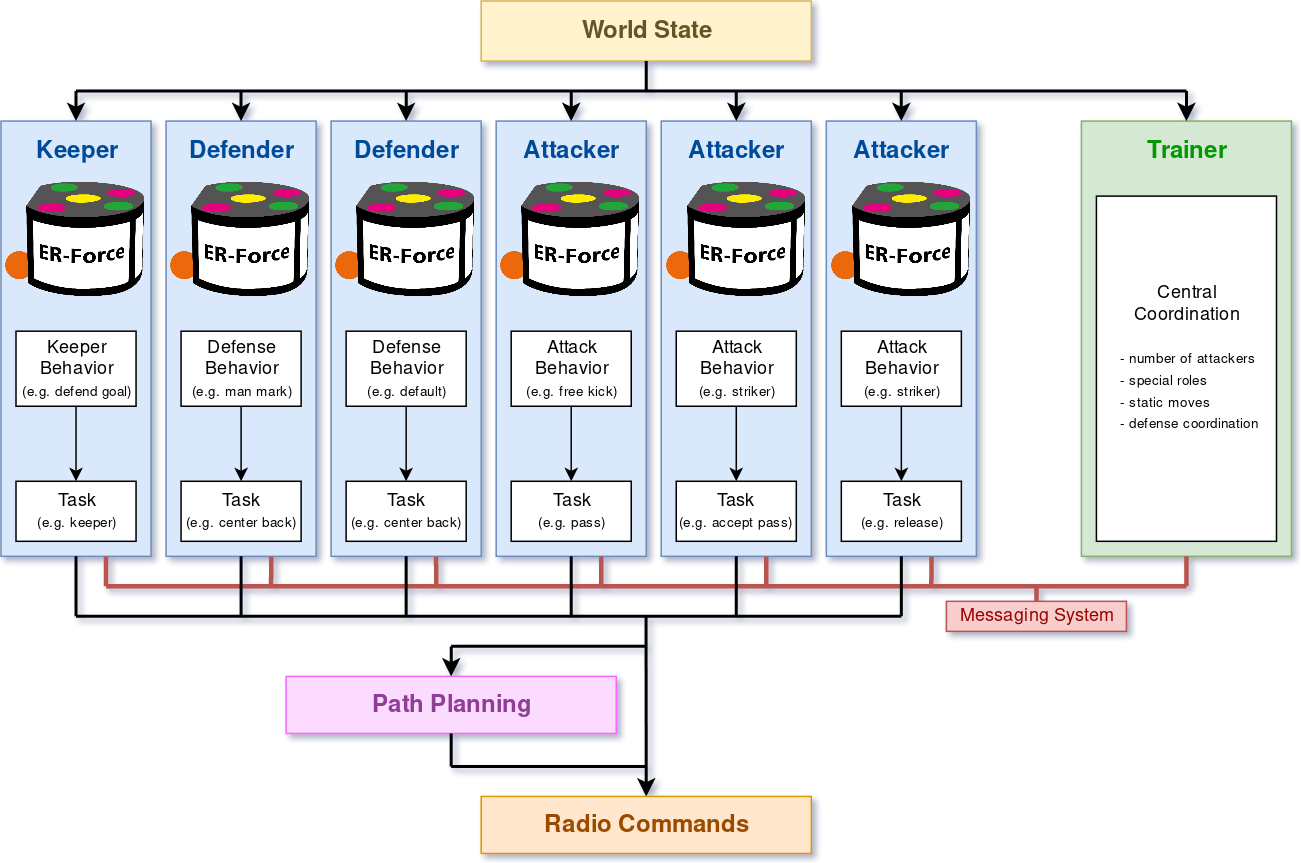 Obwohl der ganze Strategiecode auf einem einzelnen Computer läuft, verwenden wir eine verteilte KI-Architektur. Kurz gesagt bedeutet das, dass jeder Roboter seine eigenen Entscheidungen trifft. Es gibt kein zentrales Modul, das den Robotern sagt, was sie tun sollen. Technisch trifft jeder sogenannte Agent (blaue Box) die Entscheidung für den Roboter, den er bedient.
Obwohl der ganze Strategiecode auf einem einzelnen Computer läuft, verwenden wir eine verteilte KI-Architektur. Kurz gesagt bedeutet das, dass jeder Roboter seine eigenen Entscheidungen trifft. Es gibt kein zentrales Modul, das den Robotern sagt, was sie tun sollen. Technisch trifft jeder sogenannte Agent (blaue Box) die Entscheidung für den Roboter, den er bedient.
Da Fußball aber ein Mannschaftsspiel ist, muss eine gewisse Abstimmung stattfinden. In unserem Fall wird dies durch zwei Schlüsselelemente gelöst:
- DasNachrichtensystem ist eine Möglichkeit, Informationen über die KI zu verteilen. Jeder Agent kann seine Entscheidungen bekannt geben, Angriffsmanöver vorschlagen oder sich um Sonderrollen bewerben. Die Nachrichten werden dann zwischen zwei Frames zugestellt.
- DerTrainer ist für globale Entscheidungen zuständig, wie zum Beispiel wie viele Angreifer wir brauchen, welcher Roboter sich dem Ball nähern darf oder welcher Gegner am stärksten verteidigt werden muss. Der Trainer kommuniziert auch mit den Robotern über das Nachrichtensystem.
Jeder Agent hat je nach Typ (Keeper, Verteidiger oder Angreifer) eine Liste möglicher Verhaltensweisen.
- Der Keeper versucht natürlich, das Tor zu verteidigen, den Ball zu klären oder gar einen Angriff einzuleiten.
- Ein Verteidiger folgt entweder einem Gegner über das Feld oder blockt Torschüsse.
- Ein Angreifer kann den Ball dribbeln, passen, Tore schießen, Verteidiger abschütteln oder den Ball erobern, wenn ein Gegner ihn kontrolliert.
Der Zweck des Verhaltens ist dann zu entscheiden, was zu tun ist. Bei einem Mannmarker kann es eine gute Strategie sein, zu prüfen, ob es möglich ist, gegnerische Pässe abzufangen. Oder was, wenn der Gegner, den der Roboter gerade markiert, bereits einen Pass erhalten hat? In diesem Fall darf der Verteidiger versuchen, den Ball zu erobern. Das gleiche Konzept wird für die Angreifer verwendet. Ein Stürmer kann entweder ausweichen, einen Pass annehmen oder einfach nur die gegnerischen Verteidiger beschäftigen. Ein Angreifer, der den Ball besitzt, kann ihn passen, auf das Tor schießen, dribbeln oder kurzzeitig abwehren.
Die Aufgabe führt dann aus, wie die Entscheidung zu realisieren ist. Die Aufgabe „Tor schießen“ berechnet beispielsweise das genaue Ziel, auf das geschossen werden soll, während die Torwartaufgabe nach einer Position sucht, an der der Roboter die Wahrscheinlichkeit eines gegnerischen Torschusses verringern kann.
Die resultierenden Befehle werden schließlich in einen Pfadplanung-Algorithmus namens Rapidly-Exploring Random Tree (RRT) eingespeist. Der Zweck dieser Phase besteht darin, einen Weg von der aktuellen Position des Roboters zum gewünschten Ziel zu finden, ohne mit anderen Robotern zu kollidieren, versehentlich den Ball zu berühren oder sich in No-Go-Bereiche (wie den gegnerischen Verteidigungsbereich) zu bewegen. Ein Flugbahnplaner glättet den Weg und berechnet eine Geschwindigkeitskurve, die dann zusammen mit Schuss- und Dribbelbefehlen per Funk an den Roboter gesendet wird.